
Hallucination occurs when AI produces confident yet false, outdated, or misleading answers. This flaw is not just inconvenient—it becomes unacceptable in high-stakes environments such as medicine, enterprise decision-making, law, and customer-facing systems.
One of the most effective ways to address this problem is Retrieval-Augmented Generation (RAG), a technique that enriches LLMs with real-time, domain-specific, and reliable data. This article will explore how RAG works, why it matters, and how it can help build more trustworthy AI systems.
The Problem of AI Hallucination
AI models like GPT-4, while highly capable, are trained on large static datasets. They learn patterns but do not have access to continuously updated knowledge or the ability to verify their own answers. As a result, when models are prompted with questions outside their training scope or containing ambiguous detail, they may generate content that “sounds right” but is factually incorrect.
Examples include:
- Citing incorrect dates or studies
- Providing outdated market or policy information
- Inventing legal clauses or technical specifications
- Offering medical recommendations without scientific support
These errors—hallucinations—can have serious or even harmful implications depending on the context. Therefore, a solution is required that allows AI to retrieve factual information during inference.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is an AI architecture that connects generative models with a retrieval system. Instead of relying solely on pre-trained data, RAG enables models to fetch external, vetted information in real-time and use it to generate more accurate responses.
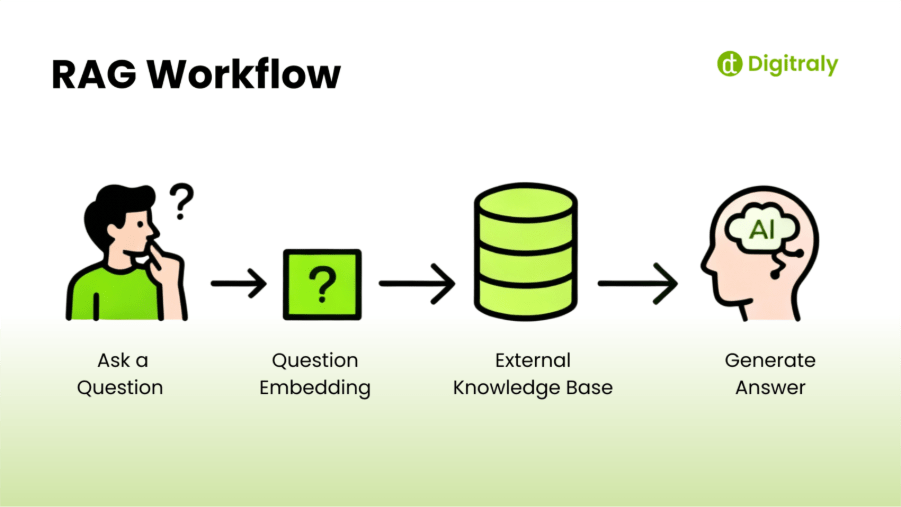
In practice:
- A user asks a question.
- The AI searches a predefined knowledge source (e.g., database, document storage, or search API) for relevant content.
- The retrieved information is added to the model’s context window.
- The model uses it to generate a grounded response.
The result is a system that provides the fluency of a large language model combined with the precision of a search engine.
Why RAG Matters
1. Minimizes AI Hallucinations
RAG dramatically reduces hallucinations by augmenting the model’s responses with authoritative data. Instead of predicting based on pattern recognition alone, the AI is guided by retrieved knowledge.
2. Enables Use of Private, Domain-Specific Data
RAG allows organizations to feed in their own internal documents, databases, or proprietary knowledge—but still leverage the natural language capabilities of an LLM. This is particularly valuable for enterprise systems, industry-specific applications, and expert domains.
3. Supports Real-Time and Dynamic Information
Unlike static model training, a RAG system can pull current information at query time. This makes it suitable for environments with frequent updates, such as news analysis, pricing systems, or financial insights.
4. Reduces Cost and Complexity
Retraining or fine-tuning LLMs is expensive and complex. RAG lets developers extend model capabilities with dynamic data systems without altering the original model. It’s modular, maintainable, and scalable.
How RAG Works: A Technical Overview
A typical RAG system involves the following components:
- LLM (Generator): The base language model that produces human-like text.
- Retriever: A search engine layer that fetches relevant documents.
- Knowledge Base: The external data source (such as cloud documents, web pages, PDFs, SQL data).
- Embedding and Indexing: Converts text into vector representations for efficient similarity search.
- Augmentation Logic: Adds retrieved content to the user query before generation.
Workflow:
- User submits a query.
- The retriever indexes and searches the knowledge base using embeddings or keyword matching.
- The top-ranked documents or chunks are appended to the model prompt.
- The LLM responds using both its internal knowledge and the augmented context.
This approach can be customized to include citations, confidence scores, or data filtering for further transparency.
Use Cases of RAG
Enterprise Assistants
Organizations can build internal knowledge assistants that understand company policies, software documentation, product catalogs, and internal reports.
Customer Support Automation
RAG-backed chatbots can reference live support ticket databases, product manuals, and policies—resulting in accurate and up-to-date service.
Healthcare and Legal AI
In regulated environments, accuracy is critical. RAG enables AI systems to ground claims in verified clinical research or statutory references.
Analytics and Business Intelligence
Non-technical users can query data sources conversationally while still receiving precise, real-data-backed answers.
Best Practices for Implementing RAG
- Ensure High Data Quality: The retrieval system is only as good as the documents it accesses. Keep source data current and well-curated.
- Chunk Large Documents: Split content into smaller blocks (e.g., 300–600 words) to improve retrieval relevance.
- Use Semantic Search or Vector Indexing: Go beyond keyword matching by using embeddings for more context-aware retrieval.
- Support Citations: Where possible, return source links or document titles along with answers.
- Monitor Retrieval Metrics: Evaluate the relevance and precision of retrieved data as part of system health checks.
The Future of RAG
As AI evolves, RAG is expected to expand into:
- Multimodal retrieval (images, tables, audio)
- Proactive agents that initiate retrieval automatically based on context
- Integrated auditing and verifiable explanations
- Memory-augmented personalized AI systems
RAG offers a scalable pathway for organizations to adopt trustworthy AI without compromising speed, budget, or private data security.
Build AI You Can Trust
Ready to bring reliable, accurate AI into your business?
We specialize in RAG-powered AI solutions that connect large language models with your real data—eliminating hallucinations and boosting performance.
Its Time Build The One
- Smart AI assistants & chatbots
- Secure, private data integration
- Fast, scalable deployment
Let’s turn your ideas into trustworthy AI—starting today.
Book a free strategy call now – https://www.digitraly.com/contact-us/


